全結合層
全結合層
全結合層とは、DeepLearningで扱う関数の中で最も基本的なもの、もしくは概念といえます。
全結合層は以下のような関数で表せます。
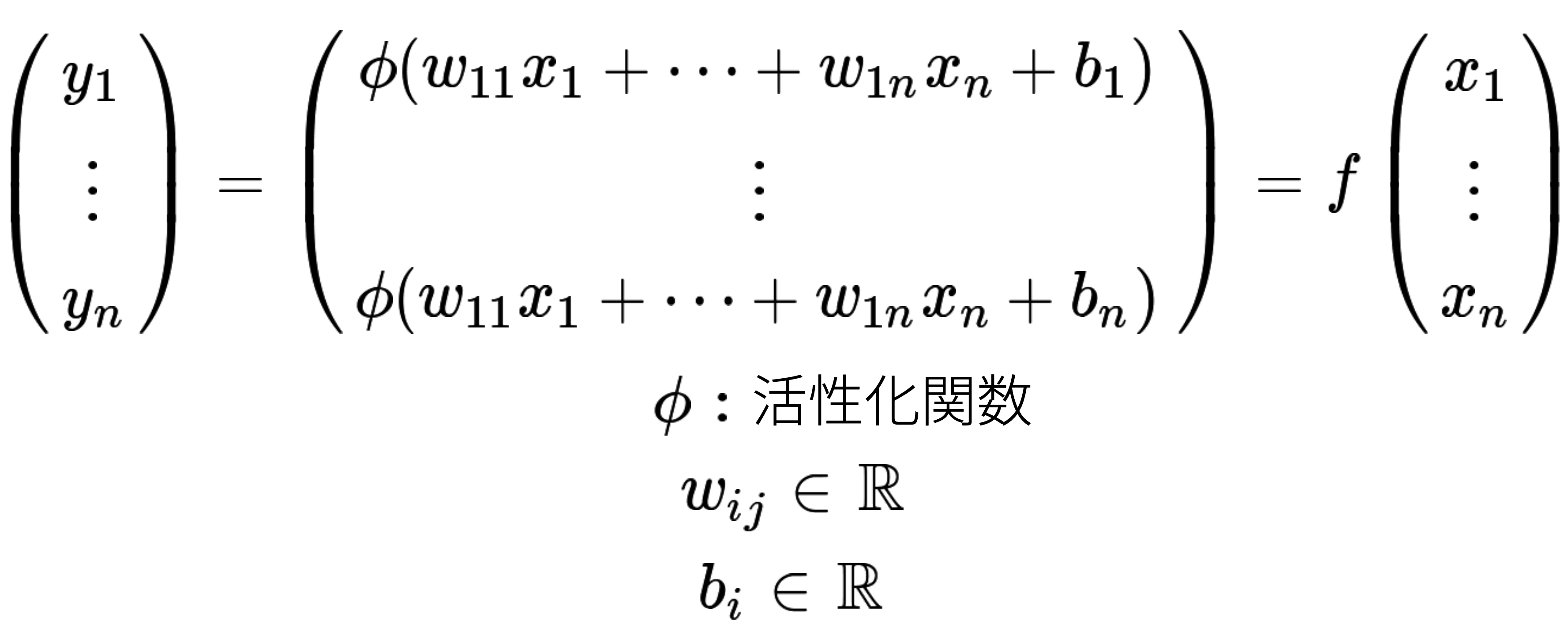
大量の入力ベクトルデータ $(x_i)_{i=1...n}$ と出力ベクトルデータ $(y_i)_{i=1...n}$ が与えられ、$\sum_{i=1}^n ((y_i) - f(x_i))^2$ が最小の値になるように $w_{ij}, b_i$ を調整します。
実際にはこれだけだと関数として十分な表現力が得られず、精度の高い関数にはならないため、これらを合成して表現力を上げ、精度を高めます。
=fk(...f2(f1(x1...xn))...).png) この関数を模式図で表現すると
この関数を模式図で表現すると
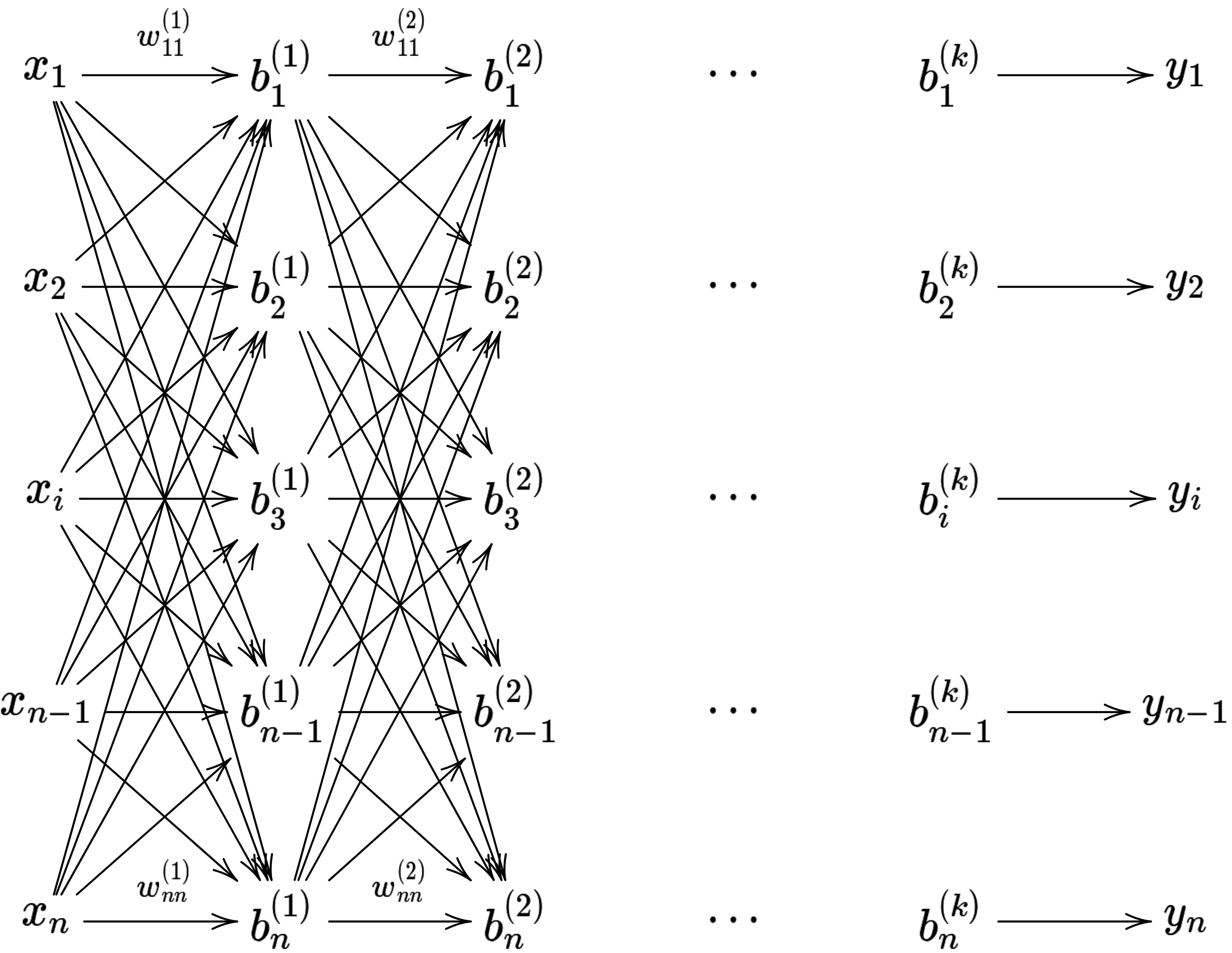
となり、これがニューラルネットワーク関数、およびディープラーニングと言われる所以となっています。
上記の例では、わかりやすくするために、入力層 $(x_i)$ , 中間層 $(b_i)$ , 出力層 $(y_i)$ を全て n 次元のベクトルとしましたが、これらは一致している必要性はありません。
扱いたいデータによりますが、通常、入力層は数千〜数百万になることはざらであり、中間層はパラメタを削減するために数百というオーダーにするケースが多いように思います。出力層も入力層同様、どのようなモデルを扱うかによりますが、数十から数万というようなオーダーになります。